


不要问我这东西到底有什么用。因为这基本上就是作弊了吧……
从by_syk的Github找到的成语数据,摘取了其中所有的四字成语,然后根据拼音拆成声母、韵母、音调(用1234表示),最后打包到sqlite3,处理用的python脚本如下:
import sqlite3
from pypinyin.contrib.tone_convert import to_initials, to_finals_tone3
import csv
# open chinese-idioms-12976.txt and read it as csv into a list
with open('chinese-idioms-12976.txt', 'r', encoding='utf8') as f:
reader = csv.reader(f)
idioms = list(reader)
res = []
for line in idioms:
if len(line[1]) == 4:
pinyin = line[2].split()
pinyin_initials = [to_initials(pinyin[i], strict=False) for i in range(len(pinyin))]
pinyin_finals = [to_finals_tone3(pinyin[i], v_to_u=False)[:-1] for i in range(len(pinyin))]
pinyin_tones = [to_finals_tone3(pinyin[i], v_to_u=False, neutral_tone_with_five=True)[-1:] for i in range(len(pinyin))]
res.append([line[1], pinyin, pinyin_initials, pinyin_finals, pinyin_tones])
# create a new database chinese-idioms.db
conn = sqlite3.connect('chinese-idioms.db')
c = conn.cursor()
# drop old table idioms if exists
c.execute('DROP TABLE IF EXISTS idioms')
# create a table idioms
c.execute('''CREATE TABLE idioms (idiom text, pinyin text, sm1 text, sm2 text, sm3 text, sm4 text, ym1 text, ym2 text, ym3 text, ym4 text, yd1 text, yd2 text, yd3 text, yd4 text)''')
# insert data into the table
for i in range(len(res)):
c.execute('''INSERT INTO idioms VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''', (str(res[i][0]), str(res[i][1]), str(res[i][2][0]), str(res[i][2][1]), str(res[i][2][2]), str(res[i][2][3]), str(res[i][3][0]), str(res[i][3][1]), str(res[i][3][2]), str(res[i][3][3]), str(res[i][4][0]), str(res[i][4][1]), str(res[i][4][2]), str(res[i][4][3])))
# commit the changes
conn.commit()
# close the connection
conn.close()代码看起来怪怪的不优雅不efficient是因为,没错,看到那些注释你就知道,我用了Github Copilot!除了瞠目结舌真的没什么别的想法了,码代码就是写小作文+Tab键。
最终生成的数据库结构是这样的:
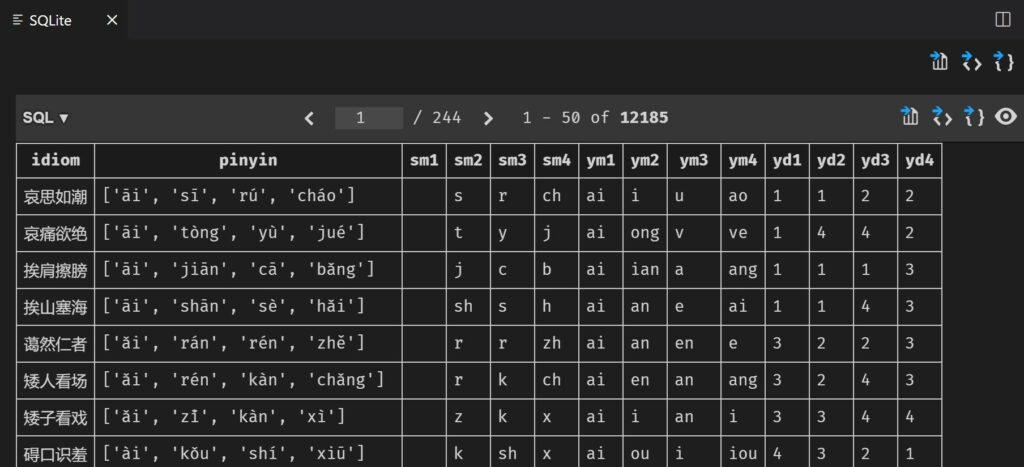
至于说你拿到这个sqlite数据库怎么用那就是你的事情了,总之拆成这样之后是很好用的。
解压之后就是chinese-idioms.db,用你最喜欢的方式去query就好啦。