


你经历过二十万行数据从另外五十万行数据里用VLOOKUP匹配的绝望吗?动辄半小时白屏未响应,难道就没什么方法可以解决吗?Fear not, this article is just for you!
更新:真·一劳永逸的解决方法
Office 365在某个版本里从源头提高了VLOOKUP的执行效率,现在已经可以无脑VLOOKUP了,氪金竟然真的可以变强。
一劳永逸的解决方法
这种数量级的破事儿为什么要用Excel?直接上数据库写查询吧,专业的东西要用专业的工具。
当然了学习成本也许有点高
毕竟不是所有人都顺便学了SQL,而且有些时候真的直接用Excel会方便一些。难道就没有什么方法能加速VLOOKUP吗?
问题的症结
基本上这种时候出现问题的公式不外乎就是精确匹配的VLOOKUP:
=VLOOKUP(要查询的数据, 在哪几列查, 取第几列, FALSE)
因为但凡用过这公式的都懂如果模糊匹配得到的结果不一定对。
问题也发生了,这个破公式在精确匹配的时候,会不厌其烦地逐字逐行匹配到底,数量少还行,一旦数量到了十万vs十万这个级别,一般企业的垃圾办公电脑跑起来就很吃力了。
时间差不多能减半的处理方法
其实用VLOOKUP也会有不爽的时候,那就是原始数据里,需要取的数据在匹配数据的左边。而VLOOKUP只能向右取值。于是用另外两个公式的combo可以完美解决这种情况,同时效率会有些许提升:
=MATCH(要查询的数据, 在哪列查, 0)
MATCH用来返回查找值在目标数组当中的位置,第三个参数0为精确匹配。也就是说,这个函数自己,可以直到你要找的值在匹配数据的第几行。
=INDEX(从哪列取, 取第几行)
没错,INDEX就是用来取给定位置的数据。
所以把文章第一个公式用这两个重写一下,就是:
=INDEX(从哪列取, MATCH(要查询的数据, 在哪列查,0))
“要查询的数据”是需要匹配的值,“在哪列查”是包含需要匹配的原始数据的那一列,“从哪列取”是需要取值的那一列。
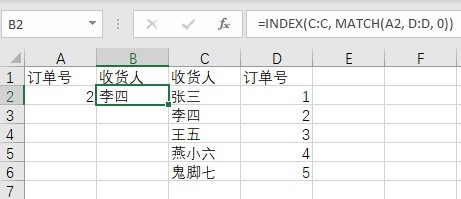
例如你要查A2的数据在D列的第几行,然后从C列取出来,这时候用VLOOKUP就很烦,因为C列在D列的左边。用这种方式,就可以无视这个问题了:
=INDEX(C:C, MATCH(A2, D:D, 0))
效果几乎完全等同于VLOOKUP,运行效率稍微高一些,但不是翻天覆地的变化。
奇技淫巧
=IF(VLOOKUP(要查询的数据, 在哪一列查(能升序排序), TRUE)=要查询的数据, VLOOKUP(要查询的数据, 在哪几列查, 取第几列, TRUE), NA())
如果你的原始数据可以排序,比如是一堆纯数字的序列号,可以直接按照数字升序排序,那你中奖了。因为VLOOKUP的模糊排序(第三个参数为TRUE)是飞快的,就是稍微比较一下数据,然后返回离查找值最接近的那个。如果有完全一致的数据,那么VLOOKUP返回值就是查找值,也就是IF公式的第一条。所以这一条就是单纯看看有没有“精确匹配”,如果返回值和查找值不同,说明没有,如果相同,说明有。因此这个判断条件只需要比对查找值和可能包含查找值的那一列而已,飞快。
如果有“精确匹配”了,就正常模糊匹配,飞快,而且一定是对的。如果没有,就返回#N/A。一整个公式和一个VLOOKUP精确匹配的效果完 全 一 致。
前提是,用于匹配出目标值的原始数据必须是排好序的。
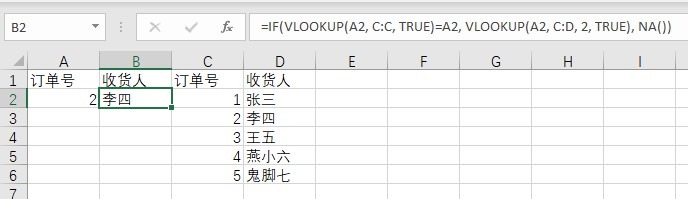
例如,你手上有一堆订单号要匹配收货人,然后有个巨大的订单信息表。你的订单号在A列,匹配的结果放在B列,巨大的订单表在C列到D列,C列是订单号,D列是收货人。
这时候,你只需要把C、D两列按C列升序排好,然后在B2输入公式:
=IF(VLOOKUP(A2, C:C, TRUE)=A2, VLOOKUP(A2, C:D, 2, TRUE), NA())
当然了,目前我测试过纯文本匹配,排个序也可以正常匹配,理论上没什么问题。实际情况请慎重
有多快呢?10分钟->1秒。
感谢分享,但看了很久没有看明白,中间的英文代表什么有点乱,如果能附上一个表格,那真能提高我们的学习效率。
更新了,现在大概能更清晰个20%😂